NVIDIA TensorRT 3大幅加速超大規模資料中心的 AI推論
阿里巴巴、百度、騰訊、京東以及海康威視等企業皆採用 NVIDIA TensorRT 開發可編程推論加速系統
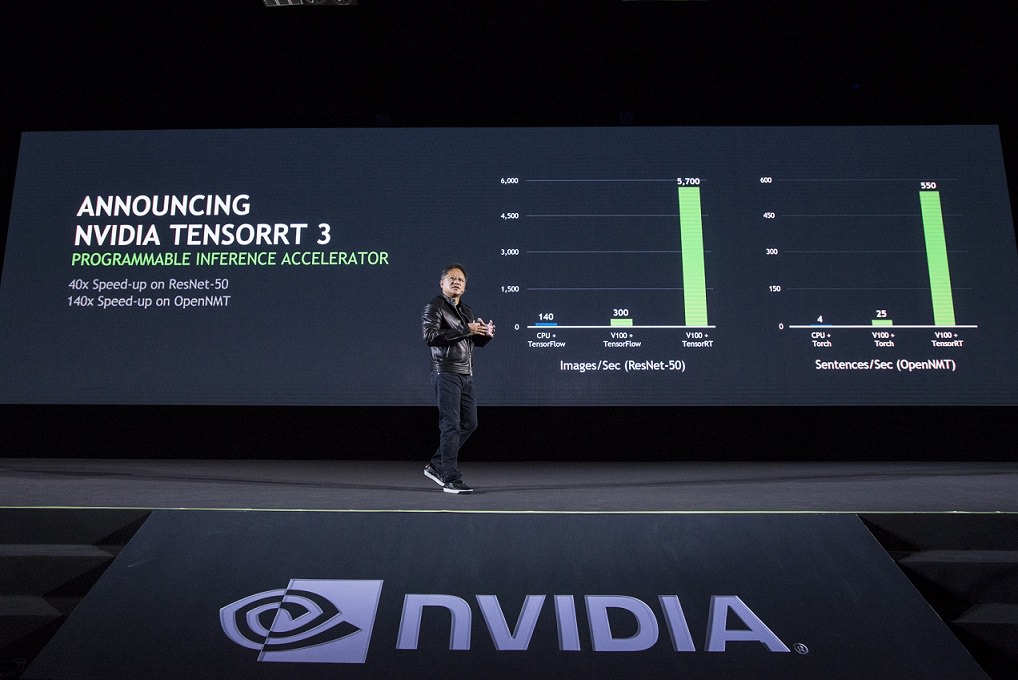
NVIDIA (輝達) 今天宣布發表全新 NVIDIA® TensorRT 3 AI 推論軟體,其針對從雲端到終端包括自駕車與機器人在內的各種裝置,大幅提升效能且同時降低成本。
TensorRT 3 與NVIDIA GPU的結合將能在各種 AI 服務應用的框架上,包含影像與語音辨識、自然語言處理、圖像搜尋以及提供個人化建議等,發揮超高速且高效率的推論運算。其中,TensorRT 與 NVIDIA Tesla® GPU 加速器的組合不僅速度比 CPU 高 40 倍(1),其成本更只有 CPU 解決方案的十分之一(2)。
NVIDIA創辦人暨執行長黃仁勳表示:「網路公司競相將 AI 導入到擁有數十億用戶的服務中,使得 AI 推論的作業負載呈直線成長。NVIDIA TensorRT 是全球首款可編程推論加速器。藉由 CUDA 的可編程特性,TensorRT將能加快推動深度學習網路的多元化應用並因應日趨複雜的演進。此外,憑藉 TensorRT 帶來的大幅加速效益,服務供應商能以低廉的成本部署這些運算密集的 AI 作業。」
橫跨眾多領域超過 1,200 家企業皆開始採用 NVIDIA 的推論平台,從龐大的資料中洞察先機,並為企業和消費者推出各種智慧化的服務。除了亞馬遜、微軟、臉書與谷歌等巨擘外,現更包含阿里巴巴、百度、京東、科大訊飛、海康威視、騰訊以及微信等中國頂尖企業。
SAP 資訊長 Juergen Mueller 表示:「在 Tesla GPU 上運行 TensorRT 軟體的NVIDIA AI平台是一項卓越的先鋒科技,能滿足 SAP 對推論運算持續攀升的需求。TensorRT 與 NVIDIA GPU 實現即時服務的傳遞,達到機器學習效能的高峰,並且發揮多元用途,滿足顧客的需求。」
京東 AI 與巨量資料部門資深經理 Andy Chen 表示:「京東旗下的資料中心仰賴 NVIDIA 的 GPU 與軟體執行推論運算。透過 NVIDIA 的 TensorRT 與 Tesla GPU,能以減少20倍的伺服器使用量,針對 1,000 部 HD 解析度的串流影片進行即時推論。NVIDIA 的深度學習平台為京東提供優異的效能與效率。」
TensorRT 3 是一款針對將 AI 部署至線上產品所開發的最佳化高效能編程器與執行引擎。其能對類神經網路進行快速優化與驗證,並將欲用來推論
之完成訓練的類神經網路部署在超大規模資料中心與嵌入式或車用GPU平台。
其提供高精度 INT8 與 FP16 浮點運算能力,讓資料中心業者省下數百萬美元的購置成本與能源消耗成本。開發者也能在短短一天內訓練出類神經網路,開發出運行速度比其訓練框架高出 3 到 5 倍的推論解決方案。
為進一步加快 AI,NVIDIA也推出其他軟體包含:
- DeepStream SDK:NVIDIA DeepStream軟體開發套件提供低延遲的大規模影片即時分析功能。其能協助開發者整合各種先進的影片推論功能,包括 INT8 精度與GPU加速轉碼,藉以支援各種 AI 服務如物體分類與情境認知,單靠一顆 Tesla P4 GPU 加速器即可即時處理 30 部 HD 解析度的串流影片。
- CUDA 9:最新版 CUDA® 是 NVIDIA 的加速運算軟體平台,藉由 支援NVIDIA Volta 架構GPU、速度提高 5 倍的函式庫、針對執行緒管理的全新編程模型以及更新版的除錯與分析工具,全面加快 HPC 與深度學習應用的速度。經過優化的 CUDA 9 能在 Tesla V100 GPU 加速器上提供極致的效能。
針對資料中心的推論
資料中心管理者必須持續在效能與效率之間取得平衡,藉以讓其伺服器主機群發揮最高的生產力。採用 Tesla GPU 進行加速的伺服器能取代超過 100 部搭載 CPU 的超大型伺服器,用來運行各種深度學習推論應用與服務,騰出寶貴的機架空間並減少耗能與冷卻設備的使用,省下大約90% 的成本。
NVIDIA Tesla GPU 加速器提供最佳的推論解決方案,在執行深度學習推論作業時能發揮最大的資料處理量、最佳效率以及最低的延遲,造就出由 AI 所驅動的嶄新體驗。
針對自駕車與嵌入式應用的推論
藉由 NVIDIA 的整合式架構,每個在深度學習框架上的深層類神經網路都能在資料中心內的 NVIDIA DGX™ 系統上進行訓練,然後再部署到所有類型的裝置 , 包括從機器人到自駕車,在終端裝置進行即時推論。
專門開發自動駕駛卡車技術的新創企業北京圖森(TuSimple)在完成 TensorRT 的優化後,使推論效能提高 30%。該公司利用 NVIDIA GPU 並以攝影機作為主要感測器,在今年 6 月成功完成從聖地牙哥到亞歷桑那州尤馬市(Yuma)的 Level 4 自駕測試,全程長達170哩。從 TensorRT 獲得的效能提升讓北京圖森除了能分析額外的攝影機資料外,還在其自動駕駛卡車中導入許多新 AI 演算法,反應時間甚至還能維持和過去相同的水準。
- 效能比較是基於在 NVIDIA Tesla V100 GPU 上運行的 ResNet-50 神經網路,並執行 TensorRT 3 RC 版,對比 Intel Xeon-D 1587 Broadwell-E CPU 運行於 Intel DL SDK的組合。兩倍跑分是英特爾對在 Skylake 核心配合 AVX512指令集能有2倍的效能提升之聲明。
- 文中比較基於 HGX-1 伺服器搭配 8 個 NVIDIA Tesla V100 運行 ResNet-50 推論運算的效能與成本,與對比一部雙插槽 Intel Skylake 橫向擴充伺服器運行 ResNet-50 的效能與估計成本。Skylake 效能的估計是根據英特爾對在 Skylake 搭配 AVX512 指令集能有2倍的效能提升之聲明。
掌握NVIDIA 最新動態
請訂閱 NVIDIA 官方部落格或追蹤 Facebook 、Google+、Twitter、LinkedIn 與Instagram。瀏覽 NVIDIA 相關影片及圖片,請至 YouTube 或 Flickr。
臉書留言